In this post you will learn how to interpolate data in a dataframe in Pandas.
There are many different methods to deal with missing values in the data. One way to get rid of NaN values is to interpolate the values in the dataframe.
How to interpolate data in Pandas dataframe
Fortunately, Pandas offers a dedicated interpolate function that interpolates values in dataframes in Pandas.
I will use an example dataframe that will show how to use the interpolate function in Pandas.
import pandas as pd
my_df = pd.DataFrame({'Id1': [1, 2, 3, 7],
'Id2': [2, 5, None, 46],
'Id3': [12, None, 5, 22]})
my_df = my_df.interpolate()
print(f'My dataframe with interpolated values \n {my_df}')
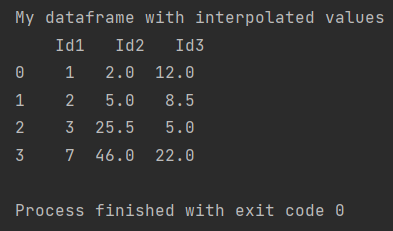
As you can see in the dataframe there were two different NaN values. Thanks to the interpolate function, Pandas inserted the values using the algorithm of my choice.
Since I did not change the default parameter in the interpolate function, Pandas inserted the values based on the linear algorithm.
Check in the documentation what possibilities the interpolate function offers.
See also:
Documentation of interpolate method
Pingback: How To Transpose A Dataframe • Pandas How To
Pingback: How To Join Two Dataframes With Different Size • Pandas How To