Here’s how to calculate standard error in Pandas.
How to calculate standard error in Pandas
In Pandas, you can calculate the standard error of the mean for a Series or DataFrame using the sem() method. The sem() method takes an optional argument called ddof which specifies the degrees of freedom. By default, ddof is set to 1, which corresponds to the unbiased estimate of the standard error.
Here is an example of how to calculate the standard error of the mean for a Series:
import pandas as pd
my_df = pd.DataFrame({"my_column1": [9, 2, 3, 5],
"my_column2": [3, 7, 6, 4],
"my_column3": [4, 8, 8, 8]})
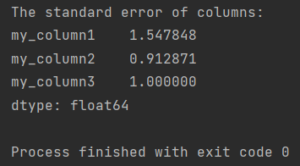
print(f'The standard error of columns:\n{my_df.sem()}')
The standard error of columns: my_column1 1.547848 my_column2 0.912871 my_column3 1.000000 dtype: float64
In Pandas, the sem method calculates the standard error of the mean for each column of a DataFrame or for each element in a Series. The method uses the formula mentioned above and returns the standard error of the mean for each column or element.
How to calculate standard error of mean in Pandas
Here is an example of how to calculate the standard error of the mean for a DataFrame:
import pandas as pd
my_df = pd.DataFrame({"A": [1, 2, 3, 4, np.nan], "B": [5, 6, 7, 8, 9]})
print(my_df.sem())
The standard error of the mean for the A and B columns is calculated separately and then returned as a Series.
You can also specify the ddof parameter explicitly. For example, the following code calculates the standard error of the mean for the DataFrame, using the biased estimate:
import pandas as pd
my_df = pd.DataFrame({"A": [1, 2, 3, 4, np.nan], "B": [5, 6, 7, 8, 9]})
print(my_df.sem(ddof=0))
The standard error of the mean is now slightly lower, since we are using the biased estimate.
For more details see the documentation of sem function.
Pingback: How To Calculate Skewness In Pandas • Pandas How To
Pingback: How To Calculate Z Score • Pandas How To
Pingback: How To Calculate Percent Change • Pandas How To